The Main Workspace
The Active Chats panel is the execution layer of your journey. This is where your initialized Personas (Mindsets), ingested Documents (Knowledge), and isolated Memory Spaces (Context) converge into an actionable runtime environment. Within MemoryBox, the primary interaction tool is the Unified Chat Bar. This interface component is structurally identical across both the initial New Chat landing view and your active, ongoing conversation logs. It provides inline access to hot-swap your context, profiles, and backend models instantly.🛠️ Building Your Prompt with Intent
The workspace composer groups all variables—Persona, Memory Space, Skills, and LLM Endpoints—directly into the input container. This keeps your settings completely at your fingertips during active conversation loops.1. Memory Space Mapping
Before initiating a query, clicking the active workspace tag within the chat bar opens the Select Memory Space popover menu.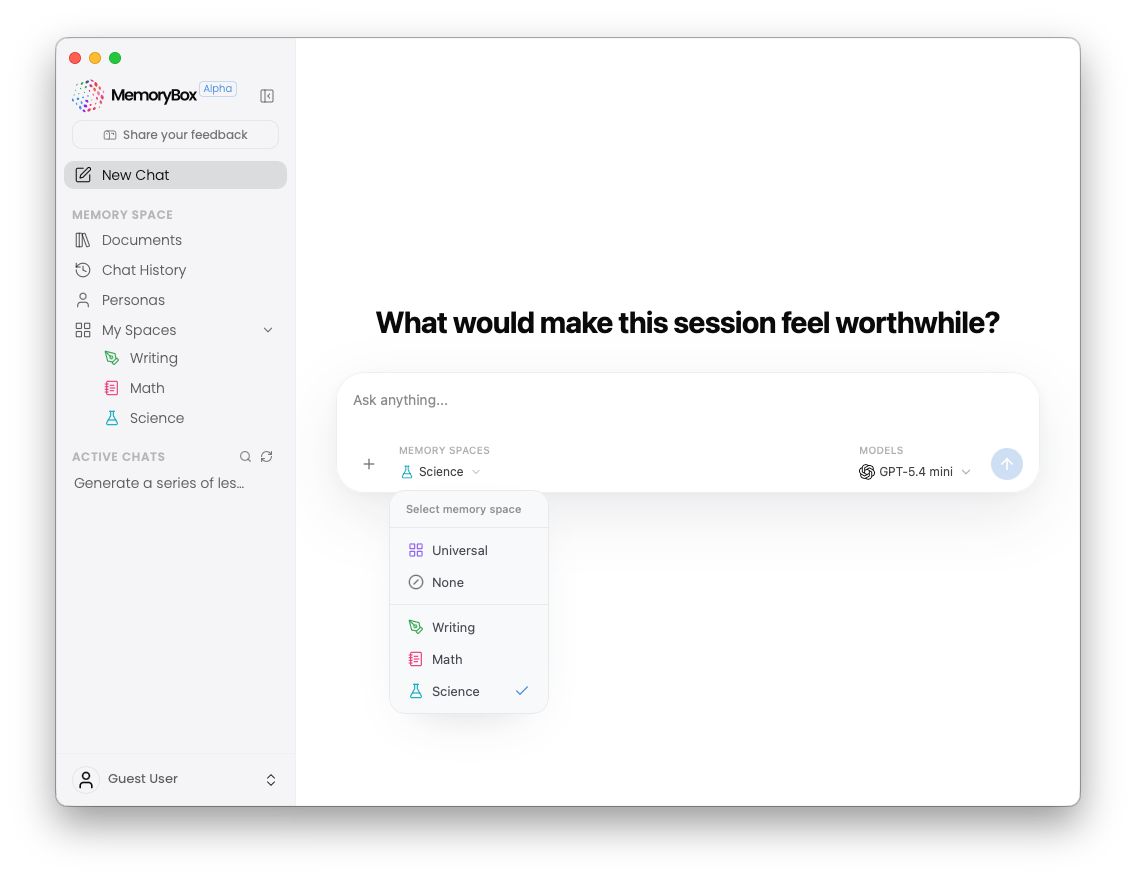
- Universal: Grants the conversation access to all files indexed globally across your local application storage.
- None: Launches a completely ungrounded session, relying strictly on the base model’s internal pre-trained parameters.
- Isolated Sandboxes (e.g., Writing, Math, Science): Restricts the execution engine to search only the vector embeddings of documents explicitly mapped to that individual folder boundary.
2. Model & Model Comparison Selection
Clicking the engine tag opens your available local and cloud endpoints. The system includes a Multiple toggle switch that changes the workspace behavior: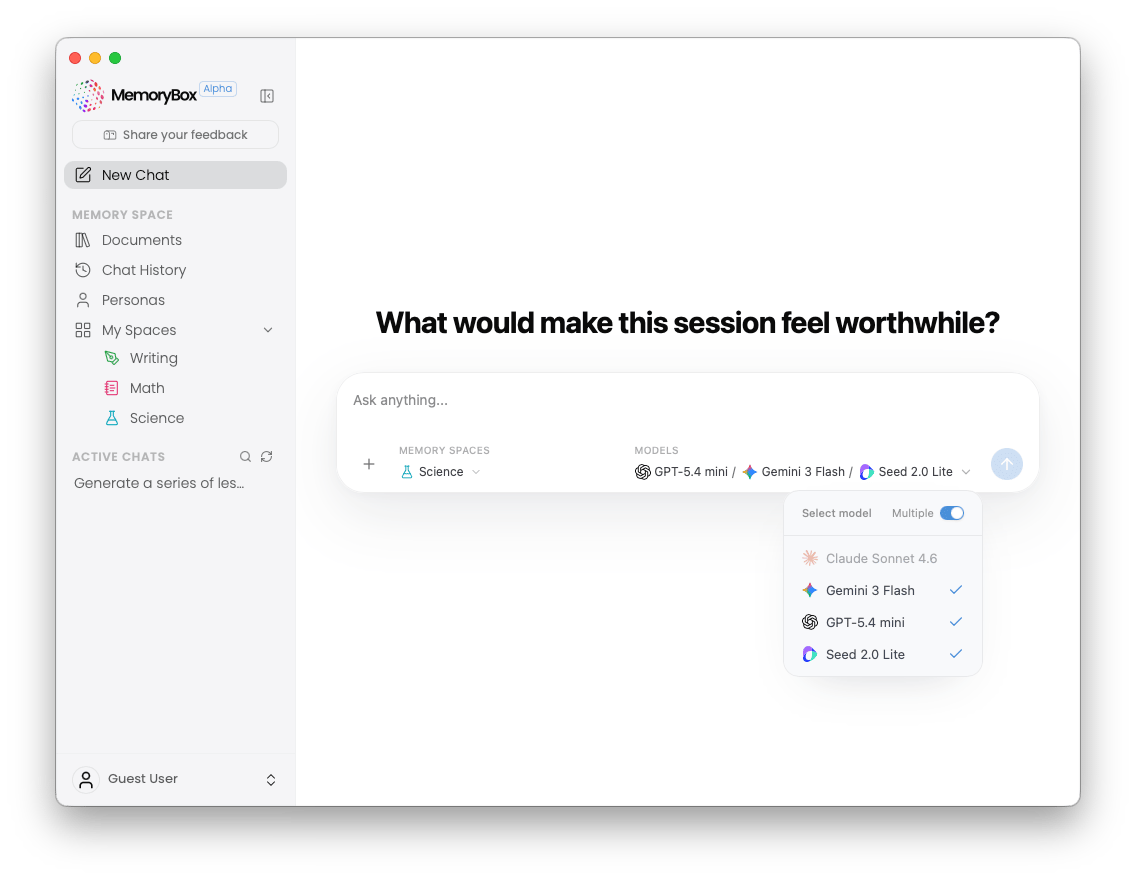
- Single Model Execution: Routes your prompt to a single high-performance engine for traditional sequential conversation.
- Multi-Model Comparison: Activating the Multiple toggle allows you to select up to three engines simultaneously. When a prompt is submitted, the platform runs side-by-side analysis, processing the exact same context query through multiple models concurrently so you can audit variations in logic, speed, and formatting.
3. Contextual Plus (+) Menu & Persona Hot-Swapping
Clicking the Plus (+) icon on the left margin of the chat bar reveals your asset injection and behavioral modification matrix:
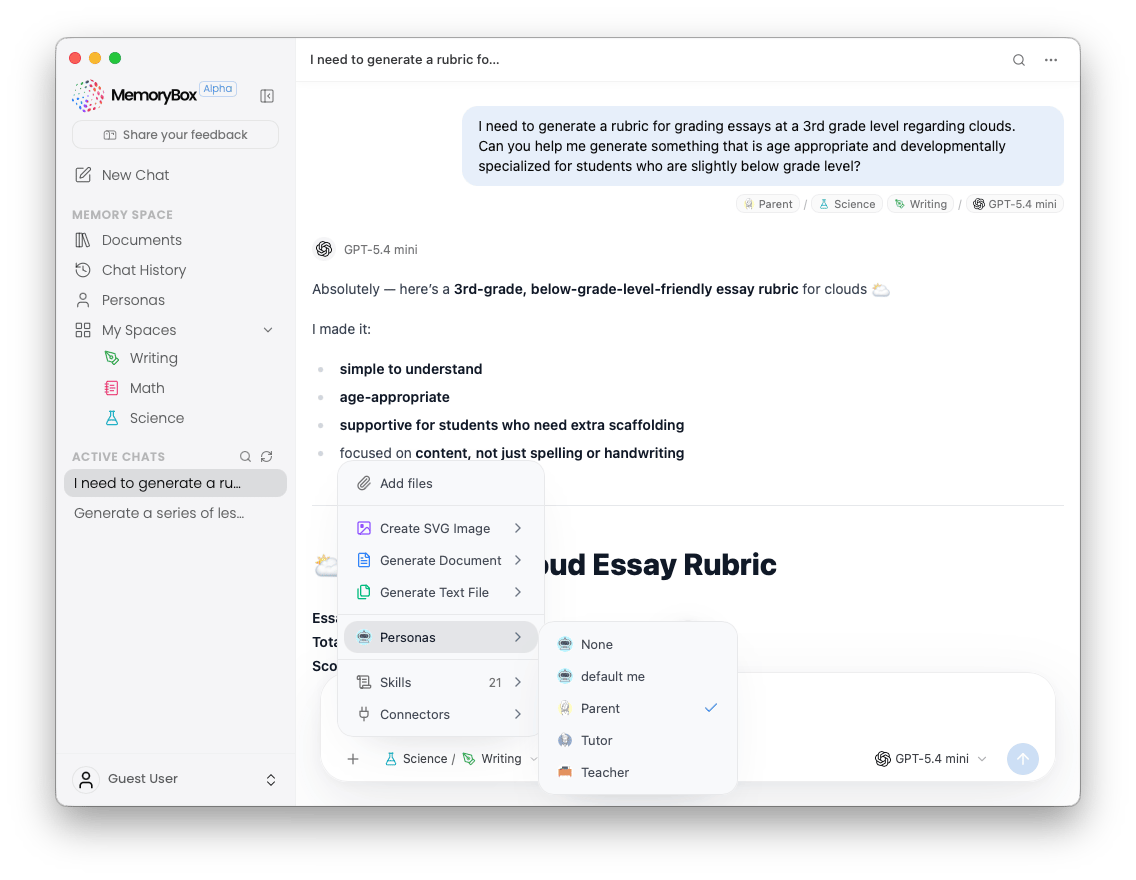
- File Actions: Upload supplementary local files directly into your workspace stream on the fly.
- Generative Tools: Initialize quick-actions to dynamically build SVG images, structured text documents, or code scripts within your active directory.
- Personas: Hot-swap your active behavioral archetype mid-conversation. Checking a new profile (such as Parent or Tutor) dynamically alters the tone, constraints, and vocabulary densities applied to all upcoming responses without destroying your chat history.
- Skills & Connectors: Fine-tune active background data tools and external data aggregators connected to the session.
💾 Session Lifecycle & Management
Once a prompt is sent from the workspace, the conversation transitions into an active running log in your sidebar layout.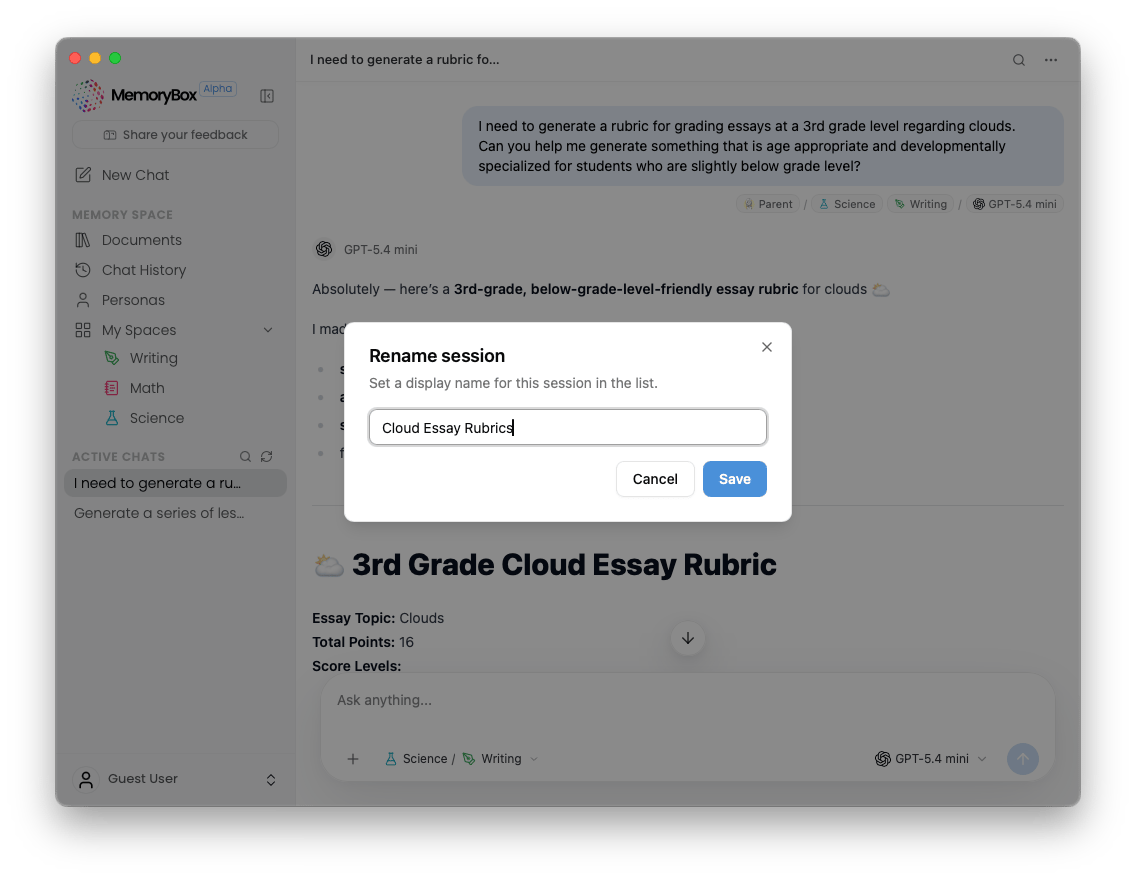
Session Persistence
Every active conversation automatically retains its assigned parameters. When shifting between different items in your sidebar navigation logs, MemoryBox automatically restores your exact chosen Persona, Memory Space configurations, and model arrays where you last left them.Renaming Chat Logs
By default, the platform generates a preview string based on your first input text. To assign a permanent, descriptive title to your workspace file log, click the ellipsis (...) menu in the top-right corner of an active thread and select Rename session to overwrite the sidebar string placeholder.
Data Traffic Transparency: When executing prompts entirely through local model architectures, your message exchanges remain completely isolated within your local device. However, if you explicitly select an external cloud endpoint provider (such as OpenAI, Anthropic, or Google), your prompt text and relevant database context fragments must be transmitted to that specific provider to generate a response.